

The Last Piece of the Puzzle
In the final part of this series, we’ll build upon the data we pulled from Tableau’s Postgres DB in part two to complete our Tableau Server Content Management Tool. This post will focus on how to use Tableau Server’s APIs to automate the process and regain valuable system resources. To complete our tool, we’ll be using the REST API and the lesser known Vizportal API. Before we being, let’s review our feature set…
1) Check for all workbooks and datasources that have not been used in N days.
2) Be able to “Whitelist” content that should not be altered. We can do this by “tagging” content directly on server and then reading those tags via the REST API.
3) Based on periods of inactivity and current schedules, decide what course of action to take: * Disable the Extract Schedule * Remove the Workbook/Datasource from Server * Reschedule the Extract to a More Efficient Time Slot
4) Send the Content Owner an email explaining the removal of their content from Server and include the .twb or .tds file as an attachment. If a thumbnail image of the Workbook is available, include that as well.
Setting up the Config
In the last post I introduced a single yaml configuration file that controls the settings needed for our tool to run. To enable our remaining features, we need to add a few more settings to it:
# Location for downloading Workbooks and Datasources from Tableau
download_settings:
download_path: '/Path/To/Where/Tableau/Content/Will/Be/Downloaded/'
# Settings for our email delivery of content messages
email_settings:
test_email: 'test@server.com' # A valid email address you can use for testing
smtp_server: 'smtp.host.com' # The SMTP hostname for your email provider
smtp_user: 'name@server.com' # A valid email that you can send messages from
smtp_pw: 'password'
notify_users: False # We'll use this as an override flag for easily disabling emails
# These settings control how we rebalance extract schedules. I'll go into more detail on this later but with this setup we can easily change our thresholds for content management
schedule_settings:
180:
Any: 'Disable'
90:
Any: 'Monthly'
30:
Weekly: 'Monthly'
Daily: 'Weekly'
Hourly: 'Weekly'
14:
Any: 'Weekly'
7:
Hourly: 'Daily'
2:
Any: 'Daily'
Now comes the fun part. Since most of what we’re looking to do is possible with the REST API we’ll start there.
Tableau Server REST API
Tableau Server ships with a really powerful set of API endpoints that can manage almost everything on our feature list.
Since we’re going to be using our config settings through out, make sure you include this block at the top of your code. I also recommend that you use an account with Server Admin privileges so you don’t run into any permissions issues.
import os, sys
from operator import itemgetter
import requests
import xml.etree.ElementTree as ET
import zipfile
import shutil
import logging #If you choose to enable logging, this library makes it really simple
import yaml
# import settings from yaml config
with open("config.yml", 'r') as ymlfile:
cfg = yaml.load(ymlfile)
tab_server_settings = cfg["tab_server_settings"]
download_settings = cfg["download_settings"]
email_settings = cfg["email_settings"]
schedule_settings = cfg["schedule_settings"]
tab_server_url = tab_server_settings['tab_server_url']
tableau_username = tab_server_settings['tab_server_url']
tableau_user_pw = tab_server_settings['tableau_user_pw']
Sign In/Sign Out of Tableau Server
Before we can manage anything, we need to authenticate and sign into Tableau Server.
Detecting Your Tableau Server & API Versions
The REST API requires that we know the version of the API we’re using and that differs depending on what version of Tableau Server you are running. You could detect this programmatically or you can refer to the chart found here. To simplify things, we’ll hardcode this for now:
api_version = '2.6' # The latest version as of Tableau Server 10.3
# We'll need this to properly parse the XML responses from our API calls
if api_version <= '2.3':
xmlns = {'t': 'http://tableausoftware.com/api'}
else:
xmlns = {'t': 'http://tableau.com/api'}
We’ll also need to be able to parse our XML responses without running into issues with unicode characters. If you’ve seen the REST API examples from Tableau, this will look familiar:
def _encode_for_display(text):
"""
Encodes strings so they can display as ASCII in a Windows terminal window.
This function also encodes strings for processing by xml.etree.ElementTree functions.
Returns an ASCII-encoded version of the text.
Unicode characters are converted to ASCII placeholders (for example, "?").
"""
return text.encode('ascii', errors="backslashreplace").decode('utf-8')
Now we can define our sign_in and sign_out functions:
Sign In
This will return the token, site_id, and user_id that we’ll need to make our other REST API calls.
def sign_in(name, password, site=""):
global token
url = tab_server_url + "api/%s/auth/signin" % (api_version)
#Build the request
xml_payload_for_request = ET.Element('tsRequest')
credentials_element = ET.SubElement(xml_payload_for_request,'credentials',name=name, password=password)
site_element = ET.SubElement(credentials_element, 'site', contentUrl=site)
xml_payload_for_request = ET.tostring(xml_payload_for_request)
#Sign in to Tableau Server
server_response = requests.post(url, data=xml_payload_for_request)
if server_response.status_code != 200:
print "Problem signing into Tableau Server: %s" % (server_response.text)
else:
print "Sign in to Tableau Server: %s" % (url)
xml_response = ET.fromstring(server_response.text)
#Retrieve the token and Site ID (we'll need these for the subsequent API calls)
token = xml_response.find('t:credentials', namespaces=xmlns).attrib.get('token')
site_id = xml_response.find('.//t:site', namespaces=xmlns).attrib.get('id')
user_id = xml_response.find('.//t:user', namespaces=xmlns).attrib.get('id')
print "Sign in to Tableau Server successful!\n"
print "token = "+token, "site_id = "+site_id, "user_id = "+user_id+"\n"
return token, site_id, user_id
Sign Out
When we’re done working with Tableau Server we need to log out and end our session.
def sign_out():
global token
url = tab_server_url + "/api/%s/auth/signout" % (api_version)
headers = {'x-tableau-auth':token}
server_response = requests.post(url, headers=headers)
token = None
if server_response.status_code != 200:
print server_response.text
else:
print "Signed out of Tableau Server successfully.\n"
return
A Note about Switching Sites
One of the most powerful features of Tableau Server is the ability to stand up separate Sites. Unfortunately, this can make managing content a bit of a bear. Workbooks and Datasources are not common across Sites and if you need to manage the content for your entire Server, you’ll probably need to do so on a Site-by-Site basis. When you sign in to Tableau Server, note how the calls require an element called the contentUrl. This is related to the Site you are logging into. In the example above, we left this blank which signs us into the Default Site. Beginning with version 10.3, Tableau has included a Switch Site endpoint which will allow you to change Sites without providing your user name and password again. If you’re running a version older than 10.3, you’ll need to repeat the Sign In step for every Site you want to manage content for.
Query Content on Server
Using the token and site_id from the sign_in function, we can now request content details from the server. We’ll keep parts of this call generic so we can use it as a template for building our other functions.
Note: This function contains 2 different endpoints, one for Workbooks and one for Datasources. Make sure you specify the correct content_type when using it.
def query_content(content_type, site_id, content_luid):
"""
Queries the server for a specific piece of content.
'content_type' is the type of content to be queried. Acceptable values are 'workbook' and 'datasource'.
'site_id' is the ID (as a string) of the site on the server where the content is located. Use the value retrieved from sign_in()
'content_luid' is the ID (as a string) of the content on the server to to be queried.
Note that this is not the same as the workbook_id or datasource_id found in the Postgres database.
It is the unique id or luid value.
Returns the name of the content and its owner_id (as a string).
"""
headers = {'x-tableau-auth':token}
# Configure call for querying Workbook
if content_type == 'workbook':
workbook_url = tab_server_url + "/api/%s/sites/%s/workbooks/%s" % (api_version,site_id,content_luid)
content_response = requests.get(workbook_url, headers=headers)
if content_response.status_code != 200:
print content_response.text
xml_response = ET.fromstring(_encode_for_display(content_response.text))
workbook_name = xml_response.find('.//t:workbook', namespaces=xmlns).attrib.get('name')
workbook_owner_id = xml_response.find('.//t:owner', namespaces=xmlns).attrib.get('id')
tags = xml_response.findall('.//t:tag', namespaces=xmlns)
workbook_tags = []
for t in tags:
workbook_tags.append(t.attrib.get('label'))
print "Workbook name = %s and is owned by %s" % (workbook_name, workbook_owner_id)
return workbook_name, workbook_owner_id, workbook_tags
# Configure call for querying Datasource
elif content_type == 'datasource':
datasource_url = tab_server_url + "/api/%s/sites/%s/datasources/%s" % (api_version,site_id,content_luid)
content_response = requests.get(datasource_url, headers=headers)
if content_response.status_code != 200:
print content_response.text
xml_response = ET.fromstring(_encode_for_display(content_response.text))
datasource_name = xml_response.find('.//t:datasource', namespaces=xmlns).attrib.get('name')
datasource_owner_id = xml_response.find('.//t:owner', namespaces=xmlns).attrib.get('id')
tags = xml_response.findall('.//t:tag', namespaces=xmlns)
datasource_tags = []
for t in tags:
datasource_tags.append(t.attrib.get('label'))
print "Datasource name = %s and is owned by %s" % (datasource_name, datasource_owner_id)
return datasource_name, datasource_owner_id, datasource_tags
Download Content from Server
Using the query_content function as a template, we can build another function to download the content which we can then archive or send as an attachment to its owner. Here are the endpoints we’ll need for downloading Workbooks and Datasources.
GET /api/api-version/sites/site-id/workbooks/workbook-id/content
or
GET /api/api-version/sites/site-id/datasources/datasource-id/content
Remove Content from Server
Use the template again to build a function for removing content, this time using the DELETE option. Here is the format of the API call from Tableau’s API Reference.
DELETE /api/api-version/sites/site-id/workbooks/workbook-id
or
DELETE /api/api-version/sites/site-id/datasources/datasource-id
Unzip Content (optional)
If you downloaded your Workbooks as .twbx files or Datasources as .tdsx files, you might want to consider only sending the .twb or .tds when you email them to their creators to save on space. The easy way to do this is to rename the file as a .zip file and then extract the Workbook or Datasource file.
You can skip this step if you downloaded your content without the data.
def unzip_content(content_type, file_name, content_name):
# Rename the file to .zip
base = os.path.splitext(file_name)[0]
os.rename(file_name, base + ".zip")
zip_file_name = file_path + content_name + ".zip"
#Extract zip file
zip_ref = zipfile.ZipFile(zip_file_name,'r')
#Location where extracted files will go
if content_type == 'workbook':
zip_ref.extractall(file_path+"Extracted Workbooks")
zip_ref.close()
print "Extract of .twb file complete\n"
#Delete everything that's not the .twb file
for f in os.listdir(file_path+"Extracted Workbooks"):
if os.path.isdir(file_path+"Extracted Workbooks/"+f):
shutil.rmtree(file_path+"Extracted Workbooks/"+f)
elif not f.endswith('.twb'):
os.remove(file_path+"Extracted Workbooks/"+f)
print "Workbook cleanup complete\n"
new_file = base.replace(download_path,'')+".twb"
elif content_type == 'datasource':
zip_ref.extractall(file_path+"Extracted Datasources")
zip_ref.close()
print "Extract of .tds file complete\n"
#Delete everything that's not the .tds file
for f in os.listdir(file_path+"Extracted Datasources"):
if os.path.isdir(file_path+"Extracted Datasources/"+f):
shutil.rmtree(file_path+"Extracted Datasources/"+f)
elif not f.endswith('.tds'):
os.remove(file_path+"Extracted Datasources/"+f)
print "Datasource cleanup complete\n"
new_file = base.replace(download_path,'')+".tds"
#Delete the zip file
os.remove(zip_file_name)
print "File "+zip_file_name+" removed\n"
return new_file
Download Workbook Images
To make our emails look professional, we can download a thumbnail of the preview image for a Workbook and include that with the .twb file.
GET /api/api-version/sites/site-id/workbooks/workbook-id/views/view-id/previewImage
Query Schedules on Server
And in order to modify content schedules, we’ll need to know what schedules are available on the server…
def query_schedules():
global server_schedules
headers = {'x-tableau-auth':token}
schedule_url = tab_server_url + "/api/%s/schedules" % (api_version)
response = requests.get(schedule_url, headers=headers)
if response.status_code != 200:
print response.text
xml_response = ET.fromstring(_encode_for_display(response.text))
server_schedules = []
schedules = xml_response.findall('.//t:schedule', namespaces=xmlns)
for s in schedules:
schedule_luid = s.attrib.get('id')
schedule_name = s.attrib.get('name')
schedule_state = s.attrib.get('state')
schedule_frequency = s.attrib.get('frequency')
schedule_type = s.attrib.get('type')
schedule_details = {'schedule_luid':schedule_luid, 'schedule_name':schedule_name, 'state':schedule_state, 'frequency':schedule_frequency, 'type':schedule_type}
server_schedules.append(schedule_details)
return server_schedules
Tableau Vizportal API
While most of what we want to achieve is possible via the REST API, there are a couple of tasks that currently aren’t possible with it but are crucial to our tool, namely working with Extracts. For those we’ll use the Vizportal API.
Note: When using Vizportal, the ID values are not the same luid values that we use with the REST API. With Vizportal, they are the numeric ID that is found in the relevant table of the Postgres DB. Since we’re coupling these calls with the data we retrieved from Postgres, you should have what you need but you may need to validate the IDs if your calls aren’t working.
Signing into Vizportal
Signing in to Tableau Server via Vizportal is a lengthy process. I won’t go into it here but you can read all about how to do that via one of my prior posts.
Update Extract Schedules
Using the Vizportal API we can change the schedule associated with an extract, like moving something from a Daily refresh to once a Week. Pay close attention to the format of the payload variable. The Vizportal API is very particular about how these are structured.
def updateExtractSchedule(task_id, schedule_id, xsrf_token):
payload = "{\"method\":\"setExtractTasksSchedule\",\"params\":{\"ids\":[\"%s\"], \"scheduleId\":\"%s\"}}" % (task_id, schedule_id)
endpoint = "setExtractTasksSchedule"
url = tab_server_url + "/vizportal/api/web/v1/"+endpoint
headers = {
'content-type': "application/json;charset=UTF-8",
'accept': "application/json, text/plain, */*",
'cache-control': "no-cache",
'X-XSRF-TOKEN':xsrf_token
response = session.post(url, data=payload, headers=headers)
if response.status_code != 200:
print "Failed to update extract schedule"
else:
print "Extract schedule successfully updated"
return response
Delete Extract Tasks
We can also use Vizportal to delete an Extract refresh task. This will not remove the content from your server, just the related Extract refresh.
def deleteExtractTasks(task_id, xsrf_token):
payload = "{\"method\":\"deleteExtractTasks\",\"params\":{\"ids\":[\"%s\"]}}" % (task_id)
endpoint = "deleteExtractTasks"
url = tab_server_url + "/vizportal/api/web/v1/"+endpoint
headers = {
'content-type': "application/json;charset=UTF-8",
'accept': "application/json, text/plain, */*",
'cache-control': "no-cache",
'X-XSRF-TOKEN':xsrf_token
response = session.post(url, data=payload, headers=headers)
if response.status_code != 200:
print "Failed to delete extract schedule"
else:
print "Extract schedule successfully removed"
return response
Emailing Users
Outside of cleaning up our server, letting our users know why we’re doing this is the next most important item. For that we’ll send them an email detailing which content is being removed, the reason why and an attachment containing the .twb or .tds file. You can also include a 2nd attachment using the thumbnail image of the Workbook (if available).
import os, sys
from os, import path
import smtplib, ssl
import mimetypes
import email
import email.mime.application
from email.mime.multipart import MIMEMultipart
from email.mime.base import MIMEBase
from email.mime.text import MIMEText
from email.utils import formatdate
from email import encoders
run_mode = tab_server_settings['run_mode']
smtp_server = email_settings['smtp_server']
smtp_user = email_settings['smtp_user']
smtp_pw = email_settings['smtp_pw']
test_email = email_settings['test_email']
# Create a text/plain message
def send_email(From, To, Subject, Reason, FilePath="", FileName="", DaysSince=""):
if run_mode == 'live':
msg = email.mime.Multipart.MIMEMultipart()
msg['Subject'] = Subject
msg['From'] = From
msg['To'] = To
file_path = FilePath
file_name = FileName
if Reason == 'Remove':
email_body = "Dear %s,\n\n Your content %s has been removed from Tableau Server because it has not been used in %s days. If you feel this has been removed in error, please notify your Tableau Server Admin or republish your content (attached).\n\n" % (To, FileName, DaysSince)
elif Reason == 'Disable':
email_body = "Dear %s,\n\n Your content %s has been disabled from updating on Tableau Server because it has not been used in %s days. If you feel this has been done in error, please notify your Tableau Server Admin or reschedule your content.\n\n" % (To, FileName, DaysSince)
# The main body is just another attachment
body = email.mime.Text.MIMEText(email_body)
msg.attach(body)
if Reason == 'Remove':
part = MIMEBase('application', "octet-stream")
part.set_payload(open(file_path+file_name, "rb").read())
encoders.encode_base64(part)
part.add_header('Content-Disposition', 'attachment; filename='+file_name)
msg.attach(part)
# send via SMTP server
s = smtplib.SMTP(smtp_server)
s.starttls()
s.login(smtp_user,smtp_pw)
s.sendmail(msg['From'],msg['To'], msg.as_string())
s.quit()
logging.info("Email sent to %s." % (To))
else:
print "DEMO MODE:Send email to %s with attached file: %s " % (To, FileName)
Connecting all of the Dots…
Now that we’ve defined all of our functions, it’s time to connect the dots and automate our process. To avoid scanning through all the content on the server and to make the script as efficient as possible, I use a Class to determine what action should be taken for each piece of content that meets the criteria we defined in tab_server_settings and schedule_settings.
Determine the Appropriate Action
class TableauContent(object):
"""
Attributes:
Required for Init:
------------------
content_name: Name of the workbook or datasource
content_type: workbook or datasource
content_id: the unique id associated with the workbook or datasource
task_id: the task_id related to the Extract refresh of the workbook or datasource
current_schedule: the current schedule type (Hourly, Daily, Weekly, Monthly) of the Extract refresh
current_schedule_id: the id associated with the current schedule
Optional:
--------
new_schedule: the schedule type to change the Extract refresh to (Hourly, Daily, Weekly, Monthly)
new_schedule_id: the id associated with the new schedule
days_since: the days since a workbook was last viewed/datasource was last accessed. Default value is Zero if not supplied during Init
action_needed: the action needed based on the criteria specified in sheriff_config.schedule_settings
"""
def __init__(self, content_name, content_type, content_id, site_id, task_id, current_schedule, current_schedule_id, new_schedule=None, new_schedule_id=None, days_since=0, action_needed=None):
"""
Returns a Content object whose name is *content_name*
"""
self.content_name = content_name
self.content_type = content_type
self.content_id = content_id
self.site_id = site_id
self.task_id = task_id
self.current_schedule = current_schedule
self.current_schedule_id = current_schedule_id
self.new_schedule = new_schedule #Default to None
self.new_schedule_id = new_schedule_id #Default to None
self.days_since = days_since #Default set to Zero
self.action_needed = action_needed #Default to None
def action(self):
"""
Returns an expected action based on the days since a Workbook as last viewed or a Datasource was last accessed.
"""
# Scan the schedule_settings from the imported config to find the action needed
for k in sorted(schedule_settings.keys(),reverse=True):
if self.days_since >= k:
# Get the correct setting based on days_since
ss = schedule_settings.get(k)
# If there is more than one setting, pull the entry that matches the current_schedule
if len(ss.keys()) > 1:
for key,value in ss.items():
if self.current_schedule == key:
cs = key
ns = value
# Otherwise use the entry that aligns with the days_since
else:
cs = ss.keys()[0]
ns = ss.values()[0]
action = ss.values()[0]
break
# If days_since does not exceed any limits in the config, apply the current settings and Do Nothing
else:
ns = 'Do Nothing'
cs = self.current_schedule
# Set the Action Needed to be Performed
if ns == 'Disable':
self.action_needed = 'Disable'
self.new_schedule = None
self.new_schedule_id = None
elif ns == 'Do Nothing':
self.action_needed = 'Do Nothing'
self.new_schedule = self.current_schedule
self.new_schedule_id = self.current_schedule_id
else:
self.action_needed = 'Reschedule'
self.new_schedule = ns
print "The action_needed for %s has been set to %s" % (self.content_name, self.action_needed)
return self.action_needed
What this does is interpret the values from our schedule_settings to come up with an appropriate action based on the guidelines below. You can customize this by changing your yaml settings but I’ve found this to be good enough for even the largest servers.
| Time Since Last Viewed/Accessed? | Current Schedule | Recommended Action |
|---|---|---|
| 6 Months+ | Any | Disable the Schedule |
| 3 Months+ | Any | Move to Monthly |
| 1 Month+ | Weekly | Move to Monthly |
| 1 Month+ | Hourly/Daily | Move to Weekly |
| 2 Weeks+ | Any | Move to Weekly |
| 1 Week+ | Hourly | Move to Daily |
| 2 Days+ | Hourly | Move to Daily |
Designing the Workflow
All that’s left is to create our workflow and connect our functions. Here’s one you can follow for Workbooks.
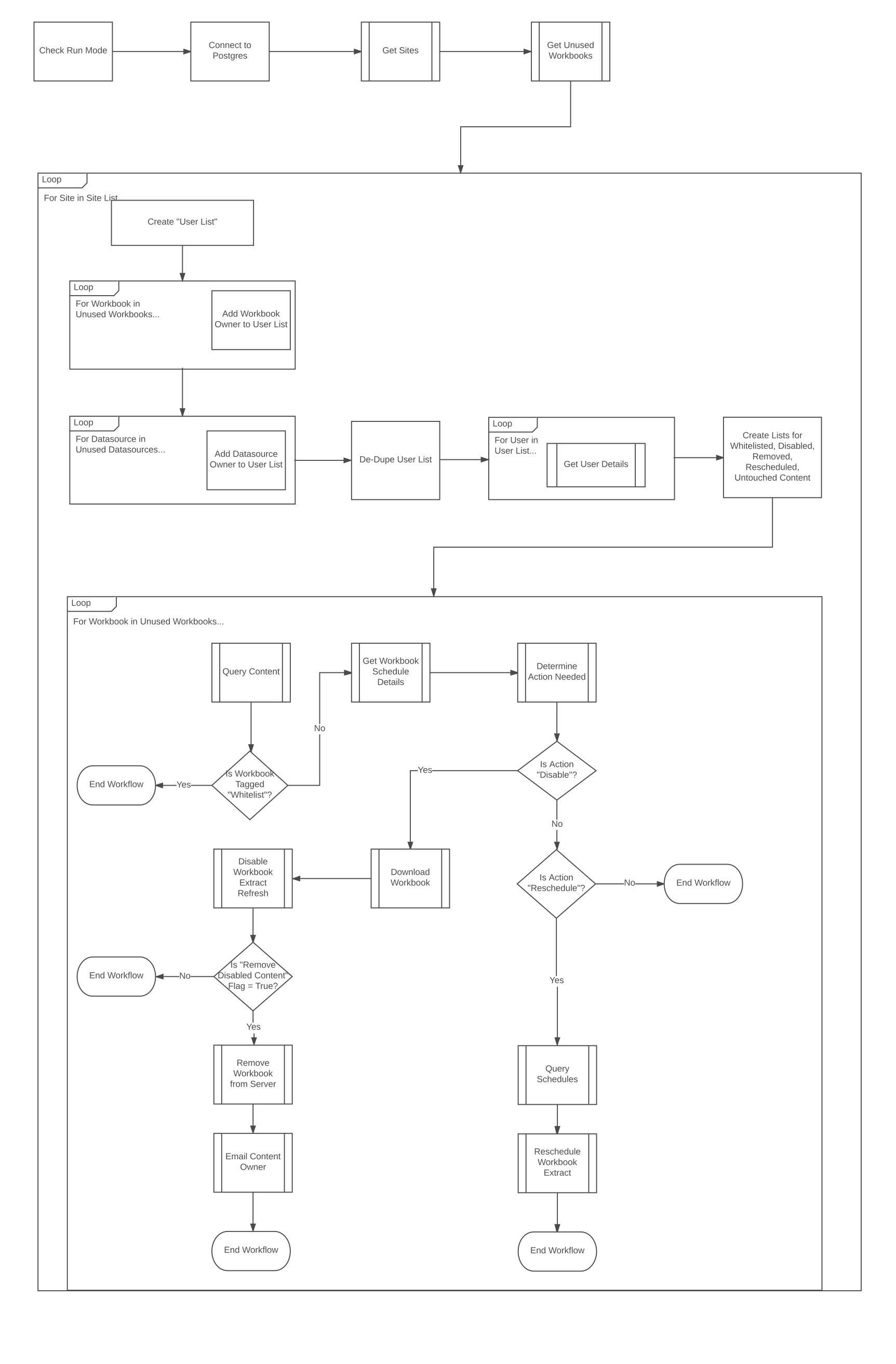
Let’s Recap
There’s a bit more work needed to get everything running, but you should now have all the pieces needed to build a robust Content Management Tool for Tableau Server. Let’s recap what we’ve built:
- We can now identify Workbooks and Datasources that have not been viewed/accessed for a given number of days. In our example, 180 days (6 Months).
- We have all of the data and functions needed to loop through the Sites on our server and take the necessary action for a Workbook or Datasource.
- We know who all of the content owners are and the email addresses associated with their server user names and built a mechanism for emailing them their content.
- We have the list of all schedules available on Tableau Server and a way to modify the schedules related to our extracts.
If you made it this far, thanks for following along. This was a really fun tool to build and I hope you learned as much as I did. I’m excited to hear about how you’ll use this knowledge to build your own tools or automate your own Tableau Server needs. If you have any questions you can reach me through any of the channels listed here on my blog.
Happy Coding!
Leave a Comment