
If you’ve ever tapped into the Postgres DB that lies at the heart of Tableau Server, you’ll find that it is a gold-mine of data about how your users interact with and experience your Tableau Server. Statistics on everything from how frequently users access workbooks, when they publish content and how well your server is performing can be gleaned from this data. And what better way to do that than by hooking up Tableau directly to get these insights.
Lots of posts have been written about how to access these tables and Tableau has published a data dictionary about what you’ll find within. There have also been numerous contributions from the Tableau Community showing what can be done with this data. Jeffrey Shaffer, who runs the amazing Tableau Blog data + science, has compiled a list of these on his Tableau Reference Guide.
Much of my client work is focused on helping organizations understand what’s going on inside their Tableau Server platforms. On a recent assignment, I had the challenge of needing to understand what was causing my client’s Extract Refresh jobs to experience long delays. I knew that by tapping into the background_jobs table I’d be able to find my answer.
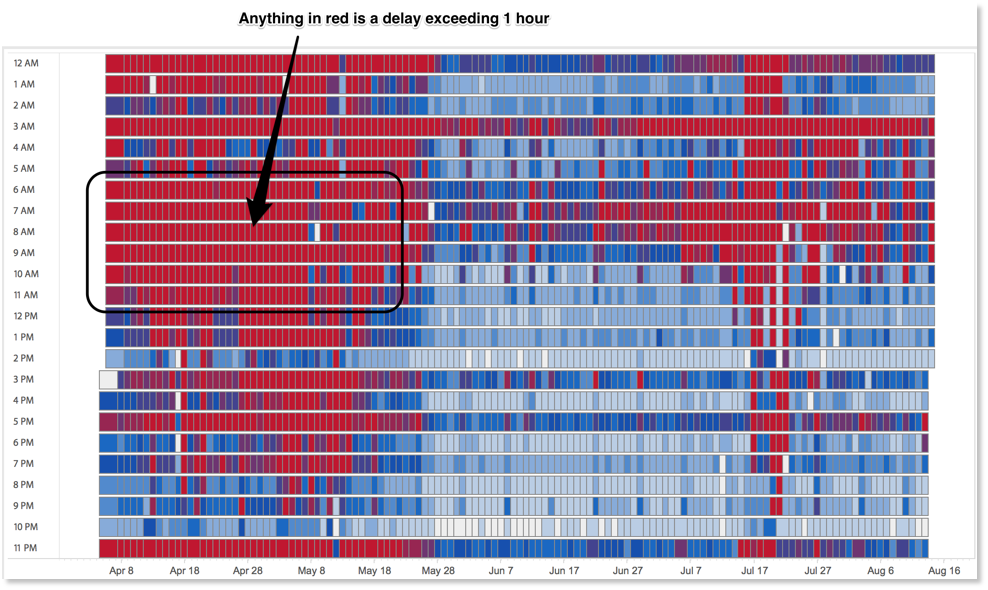
To see where the delays were, I created a heat map detailing the delays between the scheduled start time and the actual start time of each job. This showed me where the bottlenecks were but one piece was still eluding me. Specifically, I needed to connect the performance of each refresh job back to the workbook or datasource that was experiencing the delay and then to the project where it was located.
Looking for a Solution
At first this would seem like an easy task. I would just join the background_jobs table back to the workbooks table or datasources table on a common ID field and go on with my analysis. That was until I looked at the contents of these tables. The background jobs table does not contain a workbook_id or datasource_id like the other tables within the workgroup schema.
It does contain a “title” field which has the name value of the content and a “subtitle” field that displays either “Workbook” or “Datasource” if the background job is related to an Extract refresh but this is not unique.
What happens if you have a workbook in 2 different projects with the same name? How would you know you were getting the job results of the right workbook? This was indeed my problem so I began to look for a more unique way to link these tables. After all, Tableau Server has to be able to make this association so it can perform the desired operation, right?

Discovering the Link
I knew the answer had to be within the background_jobs table, so I went digging. Low and behold, I found my answer within the “args” field. For a Workbook’s Extract Refresh job, the “args” value looks something like this:
-- Workbook
-- 87994
-- (string masked for confidentiality)
-- 75596
-- null
Could one of these values turn out to be the workbook_id or datasource_id I was looking for? Turns out the ID value after “Workbook” is the workbook_id value that will tie back to the workbooks table. Having found the workbook_id, I now needed it in a format that I could use in a join. The next step requires some custom SQL and a little knowledge about regular expressions.
Using the following statement, I was able to parse the “args” string into an object_id:
cast(split_part(
(regexp_replace(args,'---','')),'- ',3
) as integer) as object_id
The statement replaces the dashes and splits the string into its own field which is then cast into an integer so it can be successfully joined with either workbooks.id or datasources.id inside of Tableau’s Data Source editor.
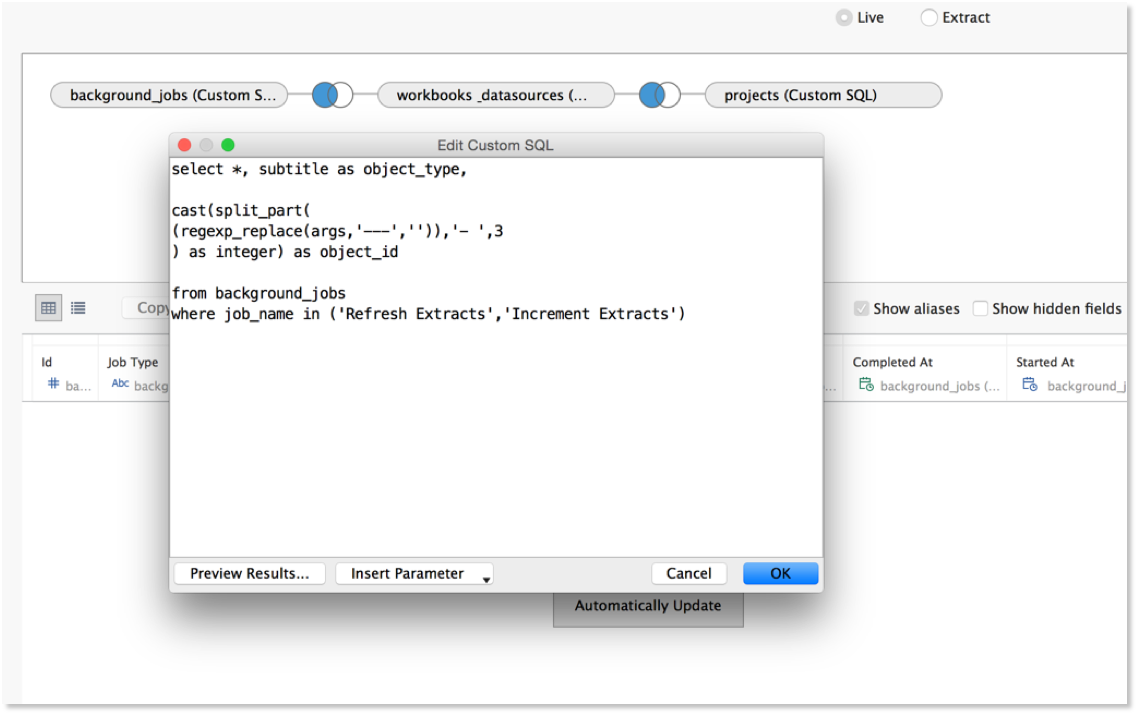
Success! I now had a version of the background_jobs table complete with the ID of the object being refreshed that I could link back to my data!
If you’re like me and you’ve been stuck searching for way to do this, I hope you enjoyed the post. I’ve created a .tds file and hosted it on GitHub so you don’t have to recreate the SQL if that’s not your thing.
Happy hunting!
Leave a Comment